Learning Pose Controllable Human Reconstruction with Dynamic Implicit Fields from a Single Image
Xinqi Liu, Jituo Li, Guodong Lu
IEEE Transactions on Visualization and Computer Graphics (TVCG), Under Reviwer, 2023
Abstract
Recovering a user-special and controllable human model from a single RGB image is a nontrivial challenge. Existing methods usually generate static results with an image consistent subject’s pose. Our work aspires to achieve pose-controllable human reconstruction from a single image by learning a dynamic (multi-pose) implicit field. We first construct a feature-embedded human model (FEHM) as a bridge to propagate image features to different pose spaces. Based on FEHM, we then encode three pose-decoupled features. Global image features represent user-specific shapes in images and replace widely used pixel-aligned ways to avoid unwanted shape-pose entanglement. Spatial color features propagate FEHM-embedded image cues into 3D pose space to provide spatial high-frequency guidance. Spatial geometry features improve reconstruction robustness by using the surface shape of the FEHM as the prior. Finally, new implicit functions are designed to predict the dynamic human implicit fields. For effective supervision, a realistic human avatar dataset, SimuSCAN, with 1000+ models is constructed using a low-cost hierarchical mesh registration method. Extensive experiments demonstrate that our method achieves the state-of-the-art reconstruction level.
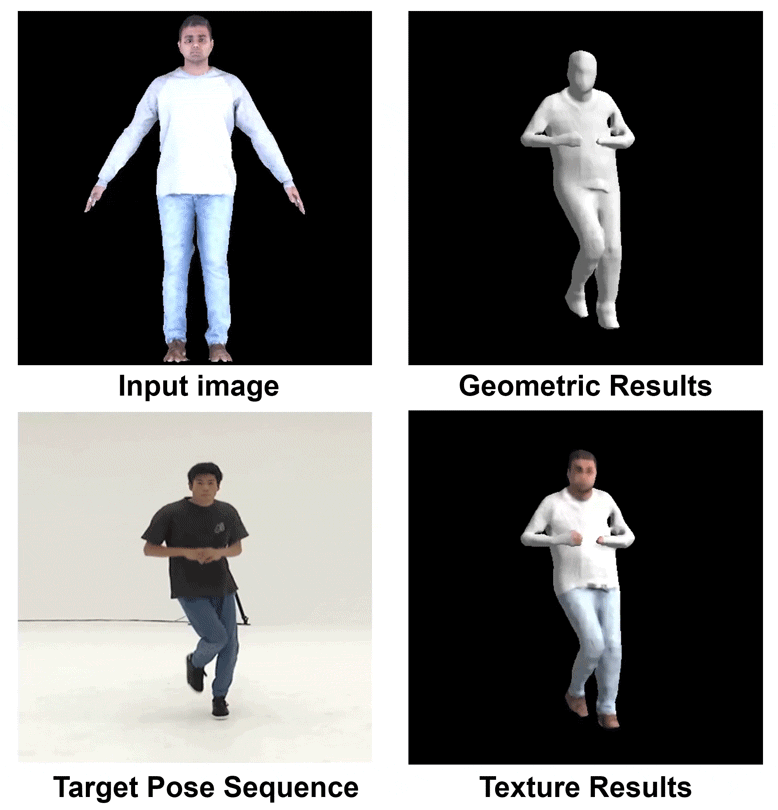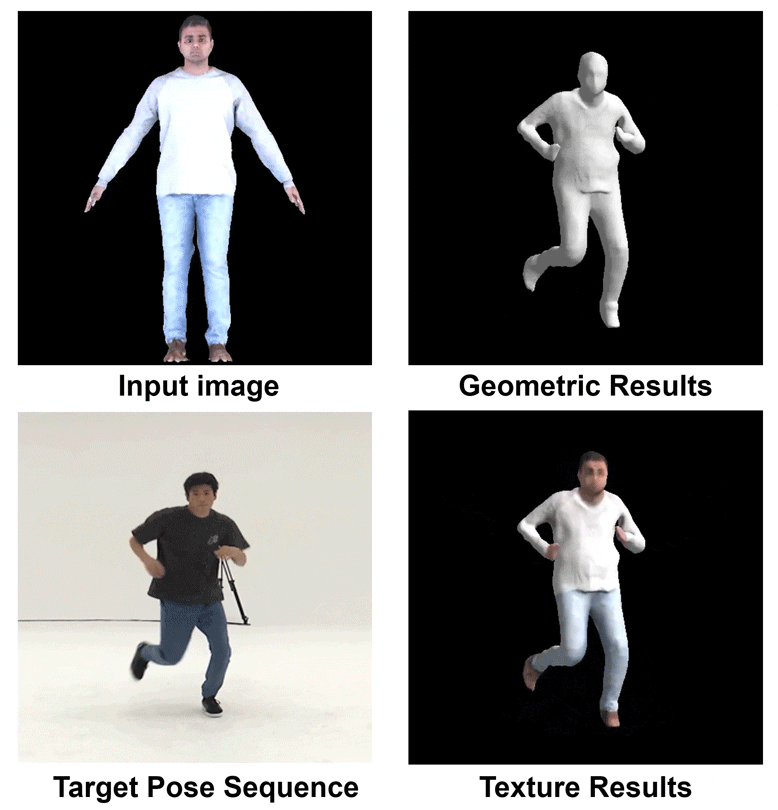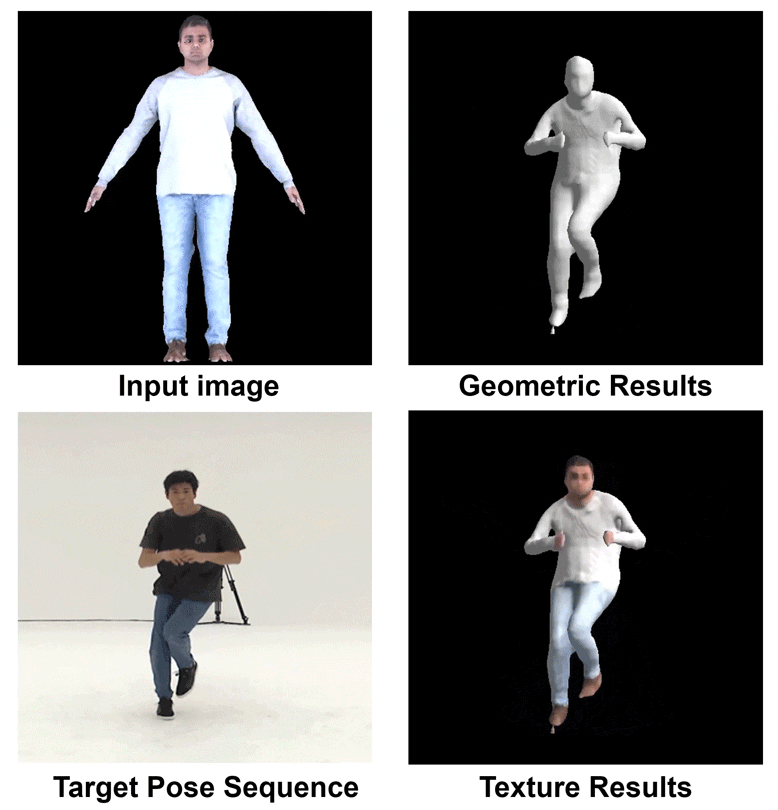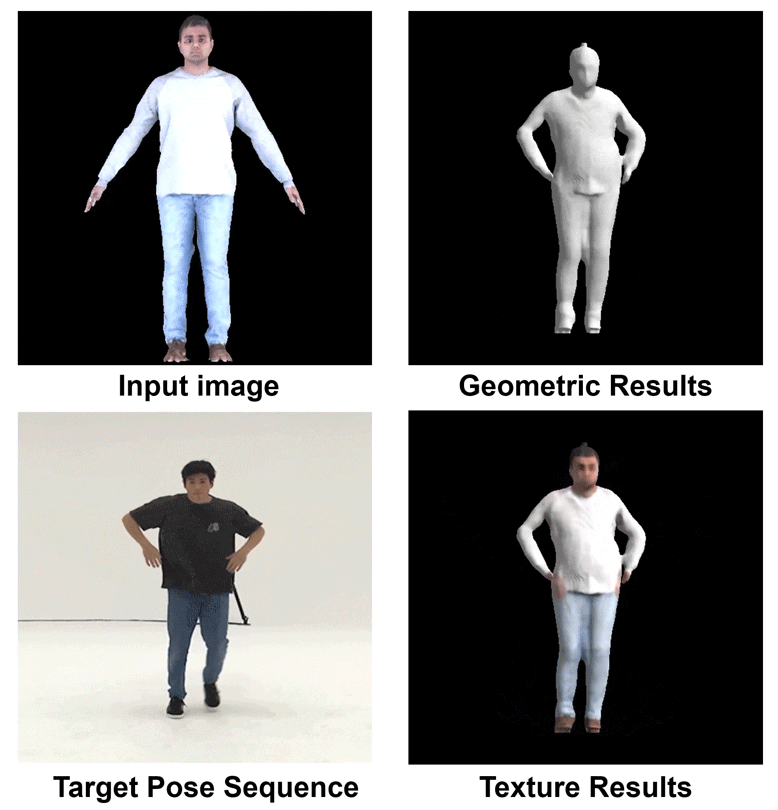
Fig 1. Our Dynamic Reconstruction Results.
Citation
Xinqi Liu, Jituo Li, Guodong Lu. "Learning Pose Controllable Human Reconstruction with Dynamic Implicit Fields from a Single Image". IEEE TVCG 2024.
@InProceedings{Liu2023DynamicField,
author = {Xinqi Liu, Jituo Li, and Guodong Lu},
title = {Learning Pose Controllable Human Reconstruction with Dynamic Implicit Fields from a Single Image},
booktitle = {IEEE Transactions on Visualization and Computer Graphics (TVCG)},
year={2024},
publisher={IEEE},
}